

皆さん、こんにちは!
上越市を拠点にし、「FA設備・装置開発」と「画像処理」に強い会社、NSIです!
私達は豊富な経験と専門知識で、各種業界の自動化・システム化のお手伝いをしています。
先日から、ついに本ブログも実運用を開始いたしました。
実運用開始後、第1回目の記事は…?
久しぶりのプログラムネタとなります。
今回はPythonでOCRを実装してみました。
PythonでOCRをしてみたい! という方にこの記事が役に立てれば嬉しいです。
OCRってなに?
OCR(Optical Character Recognition)とは、光学的文字認識 の略で、画像からテキストを抽出して認識する技術のことを指します。例えば、スキャンされた文書や手書きの文書、写真などから文字を検出して認識することが可能です。
Tesseract OCR(Pytesseract)とは?
今回は「Tesseract OCR(Pytesseract)」というOCRエンジンを使って実装していきます。
Tesseract OCRはGoogleが開発したオープンソースのOCRエンジンで、非常に高い精度が特徴です。
Tesseract の読み方は テッセラクト らしいよ。
Tesseract OCRを使う -導入編-
それでは、実際にインストールしてみましょう。
若干手順が多いですが、できるだけ詳しく解説していきます。
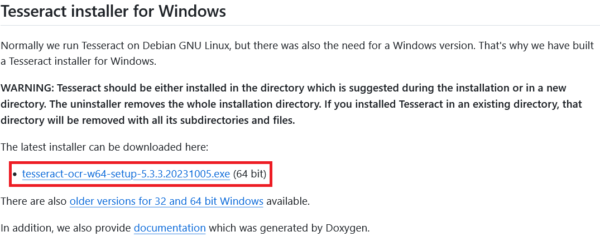
1. インストーラーのダウンロード
Tesseract OCRはPythonライブラリではないため、通常のソフトと同じくWindowsインストールが必要です。
下記のURLからインストーラーをダウンロードします。(画像参照)
https://github.com/UB-Mannheim/tesseract/wiki
2. Tesseract OCRのインストール
インストーラーを起動し、インストールを行います。
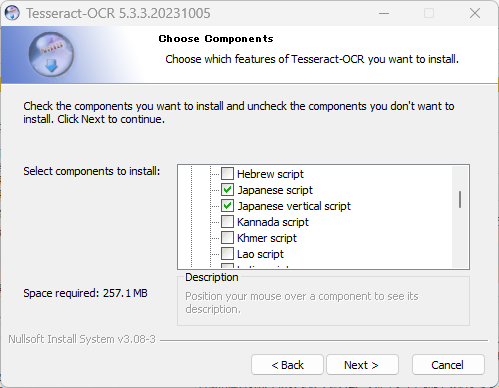
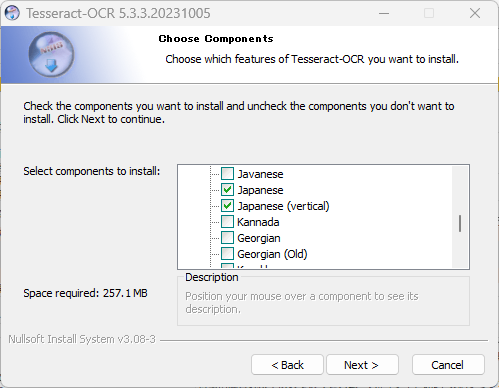
「Choose Components」という画面が表示されたら、下図のようにチェックを入れて下さい。
その他の設定はデフォルトのままで問題ありませんが、必要に応じて変更して下さい。
Additional script data (download)
Additional language data (download)
3. 環境変数の設定
環境変数に、先程インストールしたフォルダへのパスを設定します。
「システム環境変数の編集」を開き、詳細設定タブ > 環境変数 を選択します。
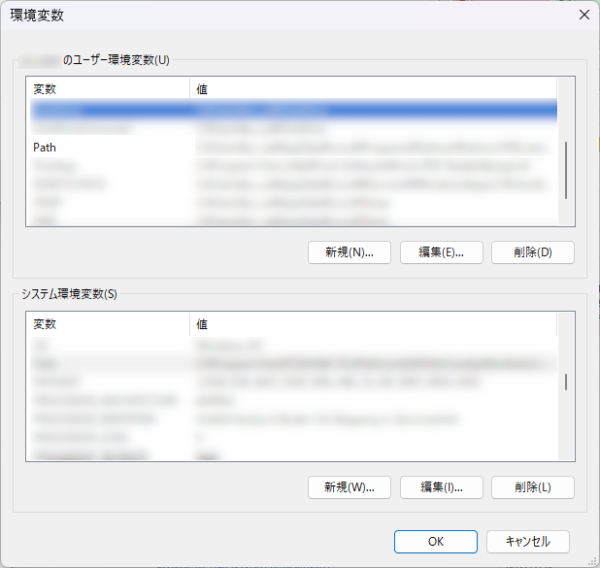
「○○のユーザー環境変数」内にある「Path」を指定した状態で「編集」を選択します。
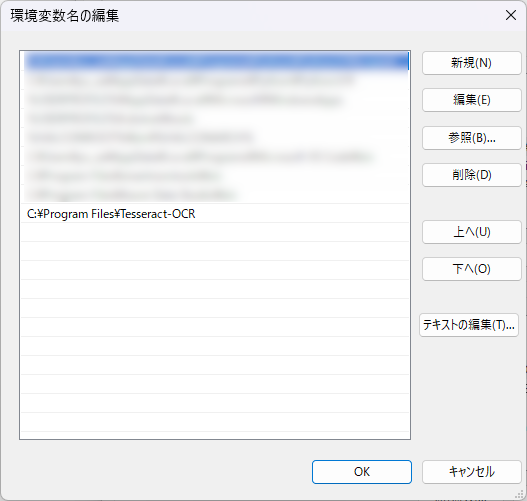
「新規」を選択し、フォルダパスを設定します。
デフォルトの場合は「C:\Program Files\Tesseract-OCR」になります。
4. Pythonライブラリのインストール
Tesseract OCRをPythonで使えるようにするため、Pythonライブラリをインストールします。
コマンドプロンプトを起動し、下記のコマンドを実行します。
※ 下記はPythonがインストールされている場合のコマンドです。別の開発環境(Anaconda)等を使っている場合は、それに合わせて変更してください。
pip install pyocr「pyocr」は、PythonからTesseract OCRを制御するためのライブラリです。
pip install pillow「pillow」はPythonから画像を扱うためのライブラリです。
補足:Anacondaとは?
簡単に言うと、Pythonでの開発に必要な「ライブラリ」や「ツール」などをセットにした実行環境。
Pythonでは、必要なライブラリを「pip install ~」で1つずつインストールする必要があるが、Anacondaはインストール時にある程度のライブラリも含まれているため、わざわざインストールする手間がないのがメリット。
多様な機能が含まれている分、Pythonよりも容量を必要とするのがデメリット。
Tesseract OCRを使う -実装編-
続いて、OCR処理を実装していきます。
今回は、画像読込→ OCR実行 → 検出した文字列をテキスト出力 という処理を作成しました。
詳しい解説は以下に続きます。
import pyocr
from PIL import Image
# OCRエンジン指定
tools = pyocr.get_available_tools()
tool = tools[0]
# 画像読込
path = "TestImage.png"
img = Image.open(path)
# OCR実行
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
text = tool.image_to_string(img, lang="jpn", builder=builder)
# テキスト出力
with open("Result.txt","w") as f:
f.write(text)
# 完了メッセージ
print("OCR完了!")「OCRエンジン指定」では、使用するOCRエンジンを指定しています。
「pyocr.get_available_tools()」で使用できるOCRエンジンの一覧を取得しています。
今回はTesseract OCRしかないため、先頭の要素を指定しています。
「画像読込」では、OCRしたい画像を読み込んでいます。
今回はプロジェクトと同じ階層に画像があるため、相対パス(画像ファイル名のみ)を指定しています。
「OCR実行」では、OCRを実行しています。
「pyocr.builders.TextBuilder()」でOCRの方法を指定し、それを元に「tool.image_to_string()」でOCRを実行します。
OCRの方法は0~13まで指定でき、各番号の概要は下記のようになっています。(Google翻訳済)
| 番号 | 概要 |
| 0 | 方向とスクリプト検出(OSD)のみ。 |
| 1 | OSD による自動ページ分割。 |
| 2 | 自動ページ分割機能はありますが、OSD または OCR はありません。(未実装) |
| 3 | 完全に自動でページを分割しますが、OSD はありません。(デフォルト) |
| 4 | 可変サイズのテキストが1列あると仮定します。 |
| 5 | 垂直方向に整列されたテキストの単一の均一なブロックを想定します。 |
| 6 | 単一の均一なテキストブロックがあると仮定します。 |
| 7 | 画像を単一のテキスト行として扱います。 |
| 8 | 画像を1つの単語として扱います。 |
| 9 | 画像を円の中の1つの単語として扱います。 |
| 10 | 画像を1つの文字として扱います。 |
| 11 | まばらなテキスト。特定の順序にとらわれずに、できるだけ多くのテキストを検索します。 |
| 12 | OSD 付きのスパーステキスト。 |
| 13 | 生のライン。画像を単一のテキスト行として扱います。 Tesseract 固有のハックを回避します。 |
「テキスト出力」では、OCRで検出した文字列をテキストファイルに出力しています。
Tesseract OCRを使う -実行編-
検証1. キャプチャした文書
それでは、作成した処理を実行していきます。
今回は、前回のブログをキャプチャしてOCRを実行してみます。
キャプチャした画像は下図です。

果たして…?
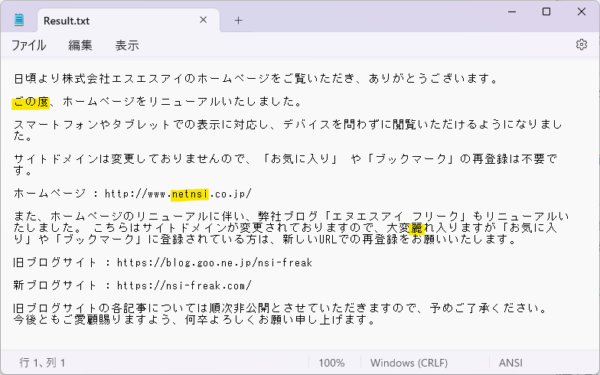
若干惜しいですが、ほぼ正確に検出できたのではないでしょうか?
検証2. 手書き文字(デジタル)
手書き文字も検出できるか検証してみました。
先程の処理を修正し、下図を参照します。

結果は…?
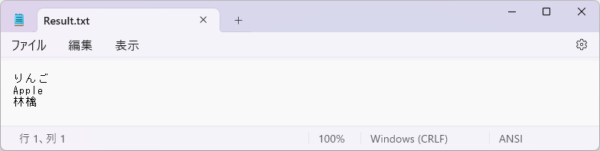
ひらがな、英語、漢字、すべて認識できました。
まさか漢字もうまく認識できるとは…!
可能性を感じるね。
最後に
今回は「Tesseract OCR」を使って、OCRを実行してみました。
これを応用すれば、手書きのメモや資料などの文字起こしができそうですね。
皆さんもぜひお試しください!
ここまで読んでいただき、ありがとうございました。
ご質問・ご要望・ご相談などは、下記お問い合わせフォームからお気軽にご連絡ください。
http://www.net-nsi.co.jp/toiawase.html

