皆さん、こんにちは!
上越市を拠点にし、「FA設備・装置開発」と「画像処理」に強い会社、NSIです!
私達は豊富な経験と専門知識で、各種業界の自動化・システム化のお手伝いをしています。
6月も中旬に入り、もうすぐ夏本番ですね。
今年の夏は平年より暑くなる予想とのこと…。
今から暑さに慣れておいた方が良さそうです。(外出たくないけど)
さて、久しぶりのPythonネタです。
今回は、PythonでWebスクレイピングする方法を調査してみました。
Webスクレイピングの概要から実装まで分かりやすく解説していきます。
ぜひご覧ください!
Webスクレイピングとは?
Webスクレイピングとは、Webサイトから自動的にデータを抽出する技術のことを指します。
これを行うには、「Webページの内容を解析し、必要な情報を抽出する」といったプログラムやスクリプトを実装する必要があります。Webスクレイピングは、データ収集、情報解析、競合調査 等、様々な用途に利用されています。
例1.価格比較
ある商品の価格を比較する際、様々なサイトを開いて調べるのはなかなか手間がかかります。
複数のサイトの価格を取得できるようにしておけば、常に最新の情報で比較が可能です。
例2.SNS分析
現代において、SNSは情報を収集するツールとして非常に有効な手段です。
SNSから投稿を収集することで、特定のキーワードに関連するトレンドをいち早く分析することが可能です。
Webサイトから必要なデータを効率的に収集できるのがメリットだね。
Webスクレイピングの注意点
Webスクレイピングを行う際、大きく分けて以下2点に注意する必要があります。
法的な問題
Webスクレイピングを実行する前に、対象のWebサイトの利用規約などから、スクレイピングが許可されていることを確認する必要があります。また、収集したデータを利用する場合、著作権侵害にならないよう注意し、個人情報を収集する場合は、プライバシー保護に十分な配慮が必須です。
技術的な問題
短期間に大量のリクエストを送信すると、Webサイトに過度な負荷をかける場合があります。
Webサイトがダウンするなどの問題が発生する恐れがあるため、負荷をできるだけ避けることが重要です。
また、Webサイトの構造が変更されると、データの収集ができなくなることがあります。
そのため、定期的にプログラムのメンテナンスも必要といえます。
補足:サイト負荷を避けるには?
さて、Webサイトに負荷がかかるとはどういう状態でしょうか?
例えば、あるWebサイトに多くのユーザーがアクセスしている状態だと、Webサイト上で「サーバーにアクセスが集中しています。」といったメッセージが表示され、アクセス制限されることがあります。これは、大量のリクエストが短期間に送信されることによって引き起こされます。
Webスクレイピングを行う際は、短期間にリクエストを送らず、HTTPリクエストの送信間隔を適切に開けることが大切です。また、事前に負荷テストを実施することで、問題が発生する可能性を下げることができます。
注意点を考慮し、適切な方法でスクレイピングするのが大事だね。
Webスクレイピングしてみる
それでは早速、Webスクレイピングを実装していきましょう!
今回は、Pythonの以下2つのライブラリを使用します。
| ライブラリ名 | 主な用途 |
|---|---|
| requests | Webサイトに対してHTTPリクエストを送信する。 |
| beautifulsoup4 | 取得したHTMLやXMLデータを解析し、データを抽出する。 |
1. ライブラリのインストール
コマンドプロンプトを起動し、以下のコマンドを実行します。
※ 以下はPythonがインストールされている場合のコマンドです。別の開発環境(Anaconda)等を使っている場合は、それに合わせて変更してください。
pip install requests beautifulsoup4補足:Anacondaとは?
簡単に言うと、Pythonでの開発に必要な「ライブラリ」や「ツール」などをセットにした実行環境。
Pythonでは、必要なライブラリを「pip install ~」で1つずつインストールする必要があるが、Anacondaはインストール時にある程度のライブラリも含まれているため、わざわざインストールする手間がないのがメリット。多様な機能が含まれている分、Pythonよりも容量を必要とするのがデメリット。
2. 処理の作成
今回は弊社HP(https://net-nsi.co.jp/)のお知らせを取得してみます。
ちょっと長くなるので、ソースコードを1つずつ解説しながら進めていきます。
まずソースコードの全文が見たい!という方は「付録. ソースコード全文」をご覧ください。
まず、Webページの内容を取得する処理を記述します。
この状態で実行すると、responseに指定したWebページの情報が入っているはずです。
import requests
from bs4 import BeautifulSoup
# データを取得したいWebページのURL
url = "https://net-nsi.co.jp/"
# Webページの内容を取得
response = requests.get(url)続いて、取得したWebページの内容を解析していきます。
取得した内容からBeautifulSoupオブジェクトを作成し、取得したい情報を取得していきます。
# 取得した内容を解析
soup = BeautifulSoup(response.content, "html.parser")お知らせを取得するには、お知らせがHTMLの何タグによって記載されているか確認する必要があります。
そのためには、Webページをブラウザで開き、ソースコードから特定する必要があります。
今回はGoogleChromeを使い、以下の手順で確認してみましょう。
- GoogleChromeでデータを取得したいWebページのURLを開く
- F12で開発者ツールを起動(右クリック > 検証 でも表示可能)
- 「…」でソースコードを展開しながら、お知らせを探す
下図の通り「<table class=”table” table-w100 table-01 table-clGR table-left”>…</table>」とある部分がお知らせとなります。これがsoup.findでデータを取得するための検索条件の元となります。
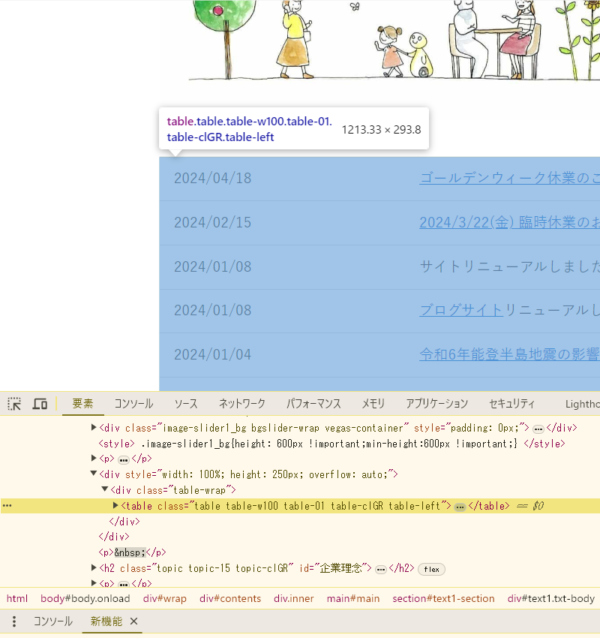
お知らせが何で構成されているかは分かったため、取得する処理(soup.find)を記載していきます。
soup.findの引数にはタグ名を指定するだけで取得が可能ですが、他に同様のタグが使用されていた場合に複数のデータが取得されてしまうため、タグ名とクラス名を指定します。
「<table class=”table” table-w100 table-01 table-clGR table-left”>…</table>」のタグは「table」、クラス名は「table” table-w100 table-01 table-clGR table-left」となります。
よって、以下のように記載します。
# お知らせを取得
news_table = soup.find("table", class_="table table-w100 table-01 table-clGR table-left")取得したお知らせテーブルから、各お知らせを取得していきます。
テーブルの行でループし、各列のデータを抽出していきます。
index = 1
# 各お知らせを取得
for row in news_table.find_all("tr"):
col = row.find_all("td")
# 列数が2のとき(日付, 内容)
if len(col) == 2:
date = col[0].get_text(strip=True) # 日付
content = col[1].get_text(strip=True) # 内容
# リンクがあれば合わせて出力
url = None
if col[1].find("a"):
url = col[1].find("a")["href"] # URL
print(f"News {index}:{date} {content} ({url})")
else:
print(f"News {index}:{date} {content}")
index += 1テーブルは「日付」「内容」の列構成となっているため、列数が2のとき という条件を元に抽出していきます。
また、内容にはURLを埋め込んでいる場合があるため、<a>タグがあればhref=の内容を取得するという処理を追加し、URLも合わせて取得できるようにします。
以上で処理は完了です。
早速実行してみましょう!
3. Webスクレイピングの実行
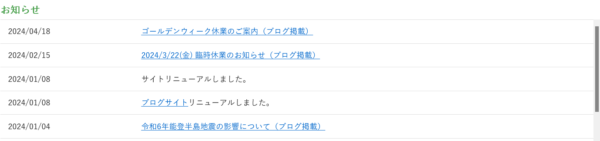
実行すると、以下の結果を取得することができました。
News 1:2024/04/18 ゴールデンウィーク休業のご案内(ブログ掲載) (https://nsi-freak.com/info-240418/)
News 2:2024/02/15 2024/3/22(金) 臨時休業のお知らせ(ブログ掲載) (https://nsi-freak.com/info-240215/)
News 3:2024/01/08 サイトリニューアルしました。
News 4:2024/01/08 ブログサイトリニューアルしました。 (https://nsi-freak.com/)
News 5:2024/01/04 令和6年能登半島地震の影響について(ブログ掲載) (https://nsi-freak.com/info-240104/)
News 6:2023/11/08 X(Twitter)開設しました。 (https://twitter.com/nsi_joetsu)実際にHPと見比べると、すべてのお知らせが取得できていることが分かります。

今回のデータ数は少なめだけど、大量のデータも一瞬で取得可能!
付録. ソースコード全文
今回作成したソースコード全文です。
(HPの更新に伴い、今後実行できなくなる可能性があります。予めご了承ください。)
import requests
from bs4 import BeautifulSoup
# データを取得したいWebページのURL
url = "https://net-nsi.co.jp/"
# Webページの内容を取得
response = requests.get(url)
# 取得した内容を解析
soup = BeautifulSoup(response.content, "html.parser")
# お知らせを取得
news_table = soup.find("table", class_="table table-w100 table-01 table-clGR table-left")
index = 1
# 各お知らせを取得
for row in news_table.find_all("tr"):
col = row.find_all("td")
# 列数が2のとき(日付, 内容)
if len(col) == 2:
date = col[0].get_text(strip=True) # 日付
content = col[1].get_text(strip=True) # 内容
# リンクがあれば合わせて出力
url = None
if col[1].find("a"):
url = col[1].find("a")["href"] # URL
print(f"News {index}:{date} {content} ({url})")
else:
print(f"News {index}:{date} {content}")
index += 1最後に
今回はPythonでWebスクレイピングをしてみました。
Webページから複数のデータを簡単に取得できるため、業務効率化に役立ちそうです。
気になった方はぜひお試しください!
ここまで読んでいただき、ありがとうございました。
ご質問・ご要望・ご相談などは、下記お問い合わせフォームからお気軽にご連絡ください。
http://www.net-nsi.co.jp/toiawase.html